Is the Future of AI Local?
Debate about whether the explosion of datacenter buildout will prove to be a worthwhile investment centers on two scenarios:
- AI adoption accelerates, the datacenter investment pays out
- AI adoption is not as fast as forecasted, and it doesn't.
However, a third scenario is very plausible:
Open source models running on local workstations dominate AI
There are a few reasons this could happen:
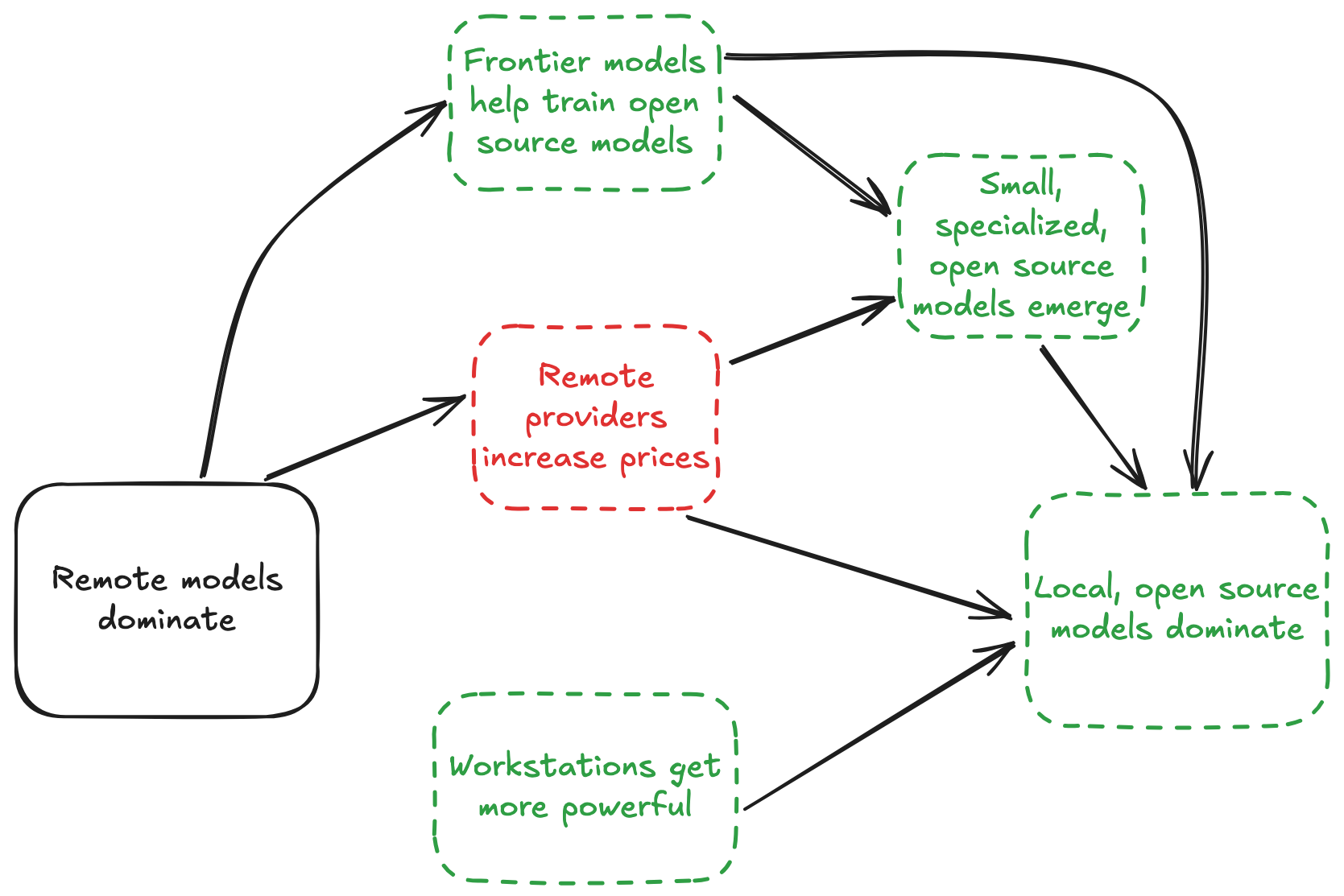
Open source models keep up
With the exception of gpt-4, open source models have matched performance of frontier models within 6 months of frontier model release (data):
Naturally, there have been accusations of open source models gaming evals, but the frontier models do the same.
We can expect this to continue. Startups usually try to create a moat, but model providers build waterslides: frontier models help train their open source competitors.
Unauthorized distillation is a difficult threat to counter. Providers can (and have) complain about competitors using their model to train competition. As a practical matter, however, this "theft"1 could be impossible to prevent.
Remote providers increase prices (or degrade subscription value)
The unit economics of frontier models are reminiscent of Uber's "cheap ride era": for example, despite $13 billion in revenue, OpenAI projects $14 billion in losses for 2026. That bill includes $8 billion in compute costs.
For Anthropic, Cursor recently estimated a $200/month Claude Max subscription can consume up to $5,000 in compute. Even before this report, they introduced rate limits on that subscription.
Their newly released Claude Code Review feature is priced at a very expensive $15-$25 per PR. Its announcement came with little explanation of why it should replace existing PR review workflows. This seems like a pricing experiment, to see how high a price enterprise is willing to tolerate.
In OpenAI's case, there is public reporting on pruning side bets and focusing on enterprise2.
Small, specialized models emerge
Given today's low prices, there is relatively little downward economic pressure on token usage. People reach for the most powerful model, regardless of the task at hand.
This will change if prices increase, and the dominant pattern of subagent-driven workflows provide a natural transition. I probably don't need a frontier model to fix style issues in my Python PR - a small, specialized model can handle that just fine. If frontier models get dramatically more (i.e. $25 per PR review) expensive, demand will increase for these models, and the open source community will be plenty able to meet it.
This is already happening on a small scale: one whitepaper claimed to get parity with GPT-4o with a fine tuned GPT-4o-mini model, at 2% of the cost.
Apple is betting on local
Apple is the lone contrarian amongst tech giants, in that they are not spending mountains of capital on datacenters:
This might be the funniest chart in tech right now.
— Josh Kale (@JoshKale) March 3, 2026
Apple's capex strategy has to be the luckiest accident in history:
Amazon, Microsoft, Meta, Google, are in a spending arms race plowing over $100B PER QUARTER into data centers - While Apple spending is down 19%
Meanwhile:
-… pic.twitter.com/12NC44DssN
Apple has been criticized for being "behind" on AI, but their bet appears to be: have competitors burn cash to train models, let advances propagate into open source models, and make devices good enough to run them.
For now, running frontier open source models requires users to buy specialized hardware. However, the most recent Macbook 4 pro Max looks to have made a leap in the size of model that's viable locally (data):
Today, running frontier models on local workstations remains out of reach. But the gap is closing.
Private and free is hard to beat
If they can gain parity with hosted alternatives, local open source models have a compelling value proposition: fast, private, and free. This possibility has not gotten much attention: no one stands to get mega-rich from them. But the threat to current leaders is a potent one.
Appendix
Open Source Parity Data
| Frontier Model | Provider | Release | Benchmark | Score | Open Source Match | OS Model | Months to Parity | Source |
|---|---|---|---|---|---|---|---|---|
| GPT-3.5 / ChatGPT | OpenAI | Nov 2022 | MMLU | ~70% | Aug 2023 | Llama 2 70B (70B) | ~9 | Stanford HAI AI Index 2025 |
| GPT-4 | OpenAI | Mar 2023 | MMLU | 86.4% | Jul 2024 | Llama 3.1 405B (405B) | ~16 | Epoch AI |
| Claude 3 Opus | Anthropic | Mar 2024 | MMLU | 86.8% | Jul 2024 | Llama 3.1 405B (405B) | ~4 | Epoch AI |
| GPT-4o | OpenAI | May 2024 | MMLU-Pro | 71.6% | Dec 2024 | DeepSeek-V3 (671B total / 37B active) | ~7 | DeepSeek V3 Technical Report |
| Claude 3.5 Sonnet | Anthropic | Jun 2024 | MMLU-Pro | 73.3% | Dec 2024 | DeepSeek-V3 (671B total / 37B active) | ~6 | DeepSeek V3 Technical Report |
| o1 | OpenAI | Sep 2024 | AIME 2024 | 79.2% | Jan 2025 | DeepSeek-R1 (671B total / 37B active) | ~4 | DeepSeek R1 via TechCrunch |
- Epoch AI: Average lag of best open-weight model behind best closed model is now ~3 months (source)
- Stanford HAI: Chatbot Arena Elo gap between closed and open models shrank from 8.04% to 1.70% between Jan 2024 and Feb 2025 (source)
On-Device Model Size
Definition: "Max usable model" is the largest Q4-quantized model that fits in device RAM and runs at ≥8 tokens/second with an 8k context window — a threshold for a responsive conversational experience. It is min(RAM-fit, speed-fit), where:
- RAM-fit =
RAM × 0.8 / 0.75— usable RAM (80% of total) divided by bytes per parameter at Q4 (~0.75 bytes/param after overhead) - Speed-fit =
(memory_bandwidth / 51.2 GB/s) × (baseline_speed / bits_per_weight) × target_t/s_factor— scales from a reference of ~11B params at 8 t/s on a 51.2 GB/s device
For MoE models, RAM-fit applies to total parameters (all weights must be loaded); speed-fit applies to active parameters only.
MacBook Pro
| Device | Year | Chip | RAM | Max Model | RAM-fit | Speed-fit | Source |
|---|---|---|---|---|---|---|---|
| MacBook Pro M1 | 2020 | M1 | 16 GB | 15.0B | 17.1B | 15.0B | Wikipedia |
| MacBook Pro M1 Pro | 2021 | M1 Pro | 16 GB | 17.1B | 17.1B | 43.9B | Wikipedia |
| MacBook Pro (M1 Pro) | 2022 | M1 Pro | 16 GB | 17.1B | 17.1B | 43.9B | Wikipedia |
| MacBook Pro M3 Pro | 2023 | M3 Pro | 18 GB | 19.2B | 19.2B | 32.9B | Apple |
| MacBook Pro M4 Pro | 2024 | M4 Pro | 24 GB | 25.6B | 25.6B | 59.9B | Apple |
| MacBook Pro M5 | 2025 | M5 | 32 GB | 33.6B | 34.1B | 33.6B | Apple Support, Apple Newsroom |
| MacBook Pro M5 Max | 2026 | M5 Max | 128 GB | 134.9B | 136.5B | 134.9B | @JoshKale |
Footnotes
-
The complaints are ironic given Anthropic's own ask forgiveness rather than permission approach to intellectual property that the providers themselves have taken. ↩
-
Granted, part of this seems to be motivated by some side bets just not getting adoption, like the Sora video generation app. ↩
Get new posts by email