MCP is a Fad
Overview
Model Context Protocol (MCP) has taken off as the standardized platform for AI integrations, and it's difficult to justify not supporting it. However, this popularity will be short-lived.
Some of this popularity stems from misconceptions about what MCP uniquely accomplishes, but the majority is due to the fact that it's very easy to add an MCP server. For a brief period, it seemed like adding an MCP server was a nice avenue for getting attention to your project, which is why so many projects have added support.
What is MCP?
MCP claims to solve the "NxM problem": with N agents and M toolsets, users would otherwise need many bespoke connectors.
The NxM problem
A common misconception is that MCP is required for function calling. It's not. With tool-calling models, a list of available tools is provided to the LLM with each request. If the LLM wants to call a tool, it returns JSON-formatted parameters:
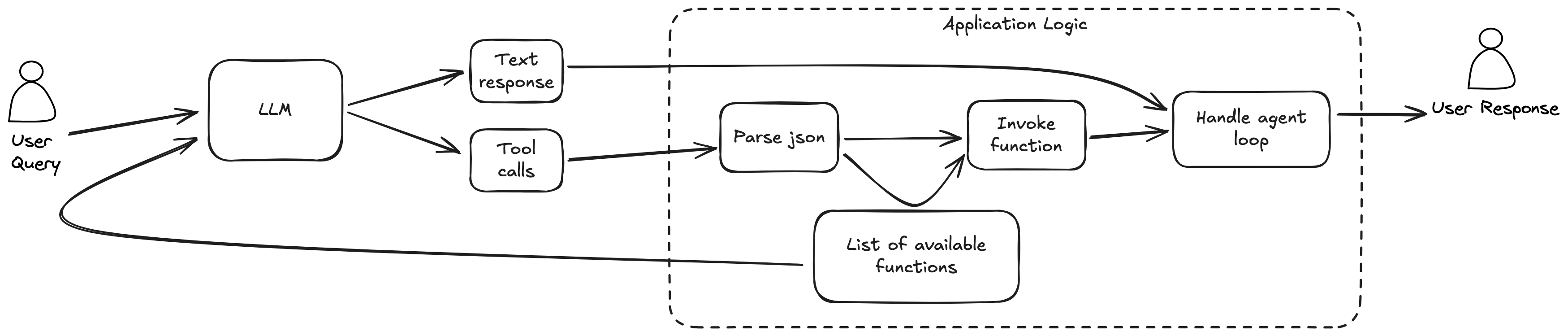
The application is responsible for providing tool schemas, parsing parameters, and executing calls. The problem arises when users want to reuse toolsets across different agents, since each has slightly different APIs.
For example, tools are exposed to Gemini's API via functionDeclarations nested inside a tools array:
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent" \
-d '{
"contents": [...],
"tools": [
{
"functionDeclarations": [
{
"name": "set_meeting",
"description": "...",
...
In OpenAI's API, tool schemas use a flat tools array with type: "function":
curl -X POST https://api.openai.com/v1/responses \
-d '{
"model": "gpt-4o",
"input": [...],
"tools": [
{
"type": "function",
"name": "get_weather",
...
This is the "NxM" problem. In theory, users must build N × M connectors. In practice, the differences are minor (same semantics, slightly different JSON shape), and frameworks like LangChain, LiteLLM, and SmolAgents already abstract them away. Crucially, these options execute tool calls in the same runtime as the agent.
How MCP addresses it
MCP handles exposing and invoking tools via separate processes:
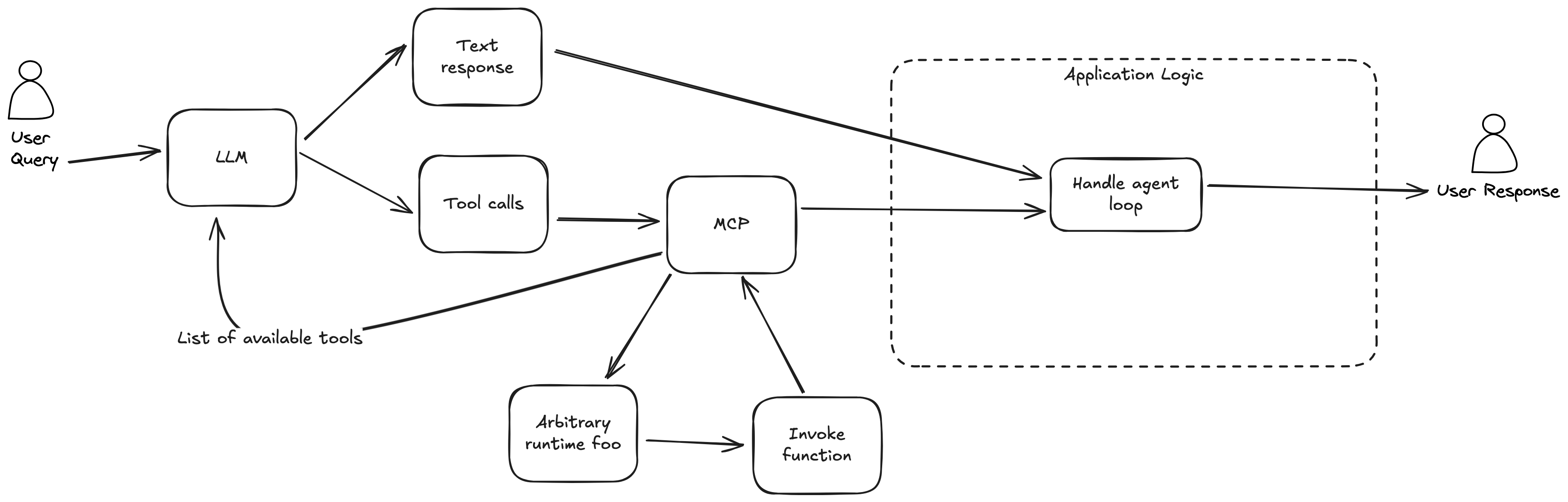
A JSON configuration controls which MCP servers to start. Each server runs in its own long-lived process, handling tool invocations independently. The application still orchestrates the agent loop and presents results to users.
This abstracts away schema generation and invocation, but at a cost. Tool logic runs in a separate process, making resource management opaque. The application loses control over tool instructions, logging, and error handling. And every tool call crosses a process boundary.
Scope: tools dominate
MCP also defines primitives for prompts and resources, but adoption of these is much smaller than tools1:
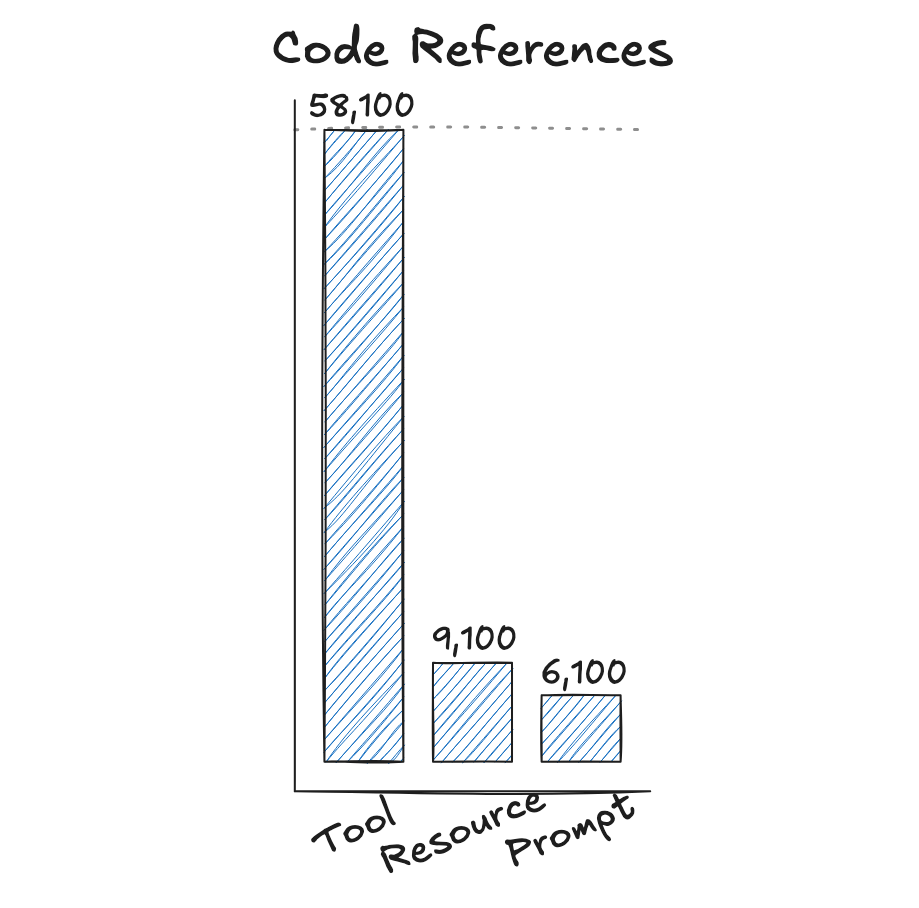
Given this, the rest of this post focuses on tool calling, which is MCP's primary use case in practice.
Problems
The convenience of MCP comes with a price, stemming from two architectural attributes of an MCP-driven application:
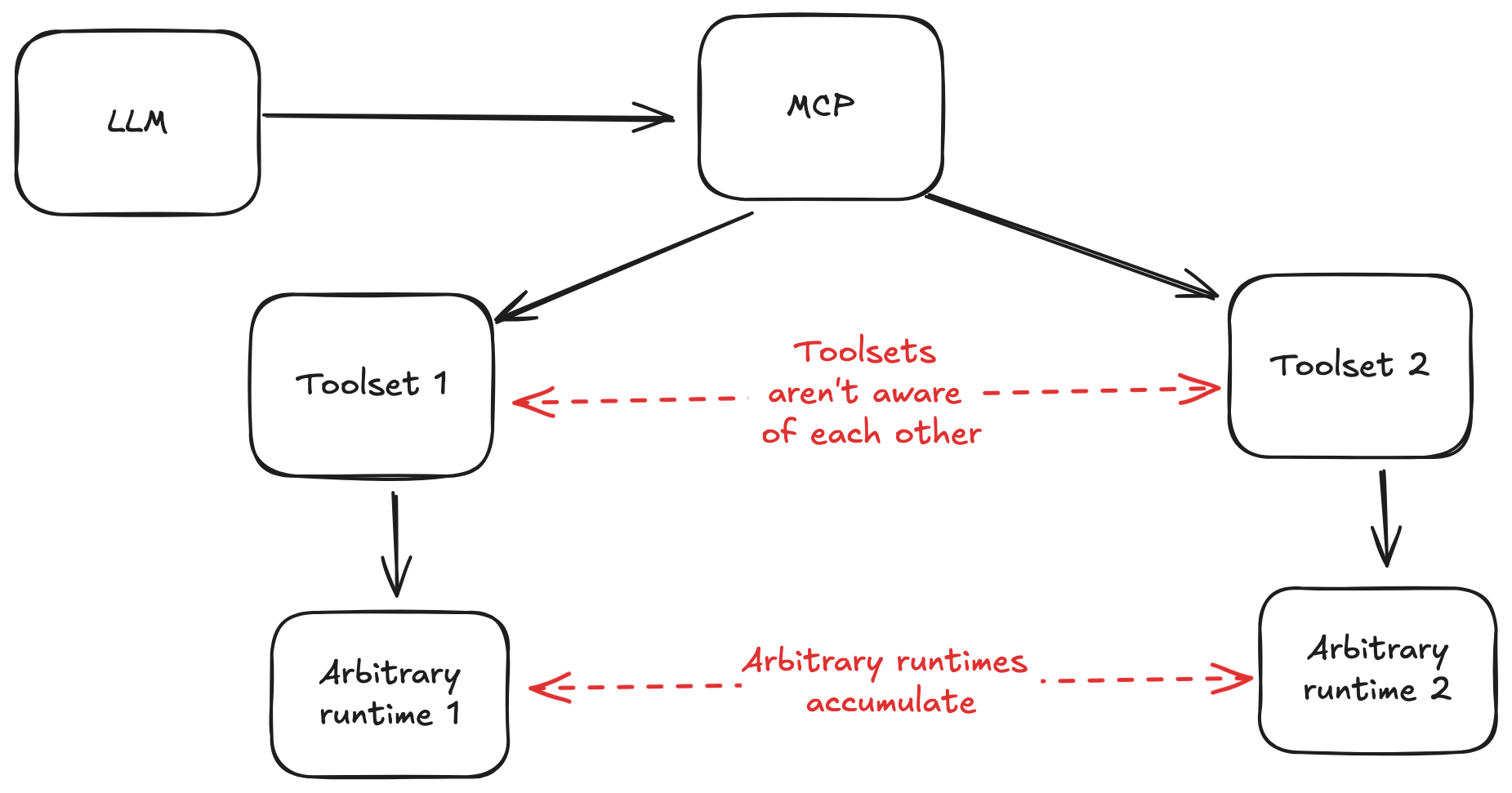
Since tools are drawn from arbitrary sources, they are not aware of what other tools are available to the agent. Their instructions can't account for the rest of the toolbox.
The second issue stems from different toolsets having their own runtimes. This introduces a variety of problems I'll discuss below.
Incoherent toolbox
Agents tend to be less effective at tool use as the number of tools grows. With a well-organized, coherent toolset, agents do well. With a larger, disorganized toolset, they struggle. OpenAI recommends keeping tools well below 20, yet many MCP servers exceed this threshold.
Why does this happen? Consider a workflow in which an agent should send a notification after doing work:
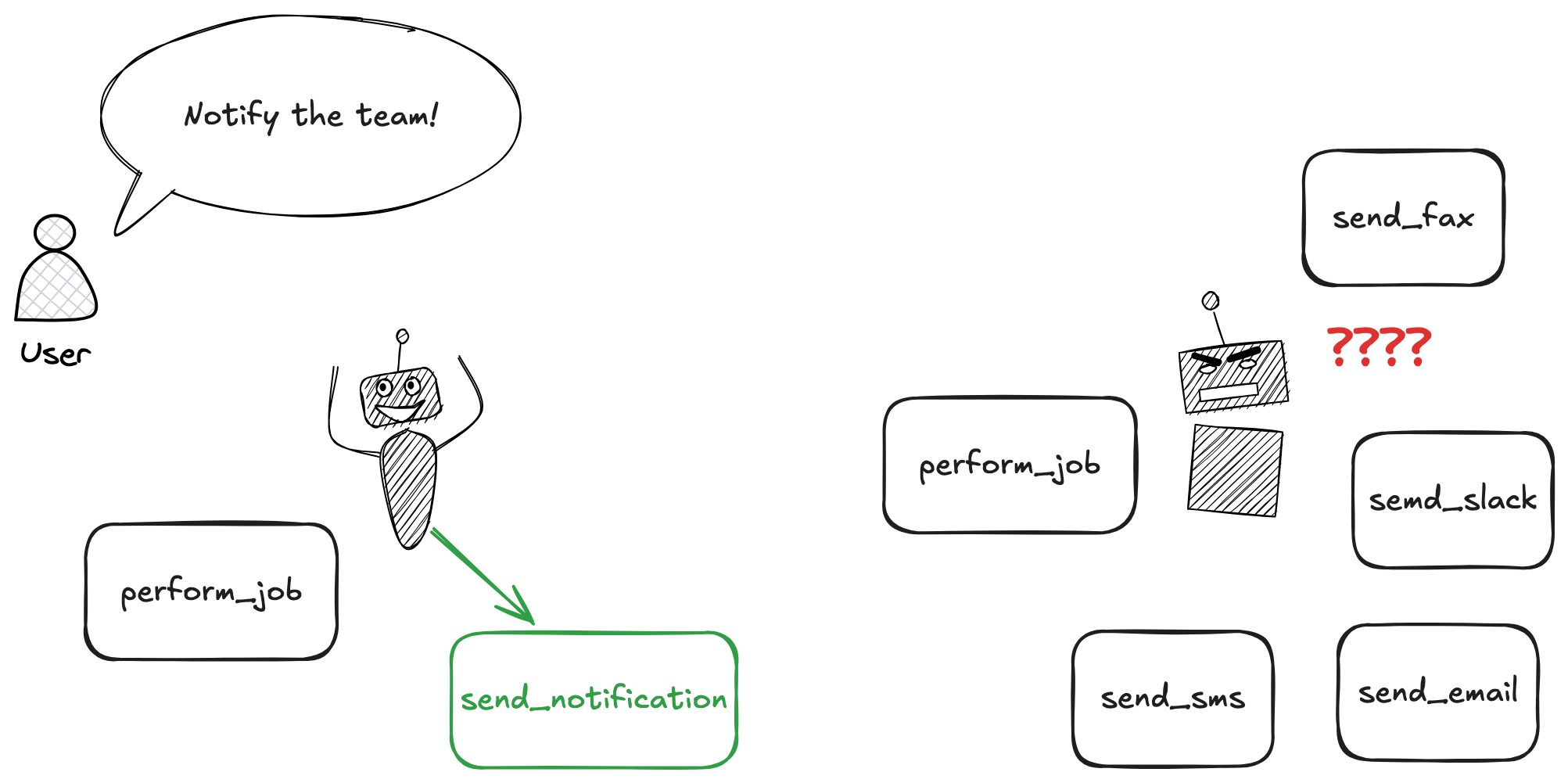
A tool's fit for a task depends not just on the job at hand, but also on what else is in the toolbox. Pliers can pull a nail, but if a hammer is available it's probably the better choice. When tools ship in isolation, their instructions can't say "use me only when you don't have a hammer," so agents don't get cohesive guidance.
If the toolset is controlled by the same authors as the application, they can add prompting to the toolsets to disambiguate when to use which tool. If not, the problem must be solved by system prompts or user guidance.
Looking through #mcp channels of open source coding agents, you'll invariably find users who struggle to get the agent to use the tools in the way they want2:

Or, users complaining of how many tokens are burned by tool instructions:

Arbitrary, separate runtimes
Each MCP server starts a separate process that survives for the length of the agent session.
Even in the healthy state, this introduces a collection of processes that remain mostly idle, aside from serving occasional requests from an agent. In an error state, we get all the usual headaches: dangling subprocesses, memory leaks, resource contention.
Users have these issues, if they are able to get the servers running at all: in support channels, the most common complaint is difficulty getting the servers to run:
MCP offers no way for servers to declare their runtime/dependency needs. Some authors work around it by baking installation into the launch command (e.g., uv run some_tool mcp), which only succeeds if the user already has the right tooling installed.
Even if the relevant package is there, the MCP server might not start it successfully. MCP servers only inherit a subset of parent ENV variables (USER, HOME, and PATH). This is particularly problematic for nvm or users leveraging virtual environments.
Python or Node developers might be comfortable debugging environment issues, (although MCP's subprocess orchestration makes this more difficult), but are likely less comfortable debugging Node issues and Python and other runtimes. MCP seems to assert that I as the user should not really care which of these are used, or how many.
Even if toolsets are in one given runtime, MCP potentially spins up many instances of it, obviating efficiencies from caching, connection pooling, and shared in-memory state. MCP's HTTP transport mode doesn't help; it's just another HTTP API, but with MCP's protocol overhead instead of battle-tested REST/OpenAPI patterns.
Security
MCP pushes users to install servers from npm, pip, or GitHub. This inherits the usual supply-chain risk, but without even the minimal guardrails those ecosystems provide. There's no central publisher or signing; anyone can ship a daemon that runs on your machine and MCP offers no provenance check.
MCP's specification doesn't mandate authentication, leaving security decisions to individual server authors. The result: one scan found 492 MCP servers running without any client authentication or traffic encryption. Even Anthropic's own Filesystem MCP Server had a sandbox escape via directory traversal (CVE-2025-53110).
MCP-related security incidents
| Issue | CVSS / Impact |
|---|---|
| CVE-2025-6514 | 9.6 (RCE in mcp-remote; 437,000+ downloads) |
| CVE-2025-49596 | 9.4 (RCE in Anthropic's MCP Inspector) |
| CVE-2025-53967 | RCE in Figma MCP Server; 600,000+ downloads |
| Asana data exposure | Tenant isolation flaw exposed ~1,000 customers' data |
Unlike a human carefully clicking through an API, agents can be manipulated via prompt injection to call tools in unintended ways. The Supabase MCP leak demonstrated this "lethal trifecta": prompt injection → tool call → data exfiltration, extracting entire SQL databases including OAuth tokens. Again, this risk isn't unique to MCP. But the best mitigations are existing security infrastructure: scoped OAuth tokens, service identities with minimal permissions, and audit logging. MCP sidesteps this infrastructure rather than building on it.
A common defense is that MCP isolates credentials—the agent talks to a socket, never seeing your API tokens. But this threat model is narrow: an agent that can invoke mcp.github.delete_repo() doesn't need your token to cause damage. You're not eliminating trust; you're redirecting it to third-party code that, as the CVEs demonstrate, is often unaudited and vulnerable.
The cost-benefit doesn't add up
These problems could be worth the cost, if we were to gain significantly. But comparing tool calling with MCP to tool calling without it, MCP handles remarkably little. MCP is, more or less, handling serializing function call schemas and responses.
The tools developers are saving themselves from having to write are, overwhelmingly, relatively thin wrappers around API clients, or utility scripts. In the former case, users must still obtain API keys, billing accounts, and so on.
This code was a hassle to write, prior to the advent of coding agents. But these small utility scripts are the precise thing that coding agents excel most at! A technical user of MCP tools will be hard-pressed to find a tool an agent could not one-shot in the programming language they are most comfortable in.
Why it took off
With these issues, it's fair to wonder why MCP has gained the popularity it has. It has had lots of support from Anthropic, and no trouble gaining traction with toolset publishers, agent providers, and enterprises. Why? It helps narratives:
Tool authors: A low overhead marketing channel
It's quite easy to publish an MCP server. The lack of startup requirements means you don't even need to publish to npm or pip: you can drop an @mcp.server annotation in your repo and host a small manifest JSON that points to your entry command (e.g., node server.js) and lists the tools.
This provides a nice narrative to gain attention to AI projects: A user can, in theory, easily add some MCP tools from a project, gain value, and follow interest in learning more about the project. Support overhead will, in the main, fall to agent maintainers.
Once publishers started appearing, it became difficult to justify not supporting MCP. Your project could be perceived as being against open standards.
Enterprise: AI credibility
Over the last few years, anyone watching San Francisco billboards has witnessed enterprise tools rebranding toward AI. MCP support provided an easy way to make your e.g. project management tool be AI. The branding of MCP as an "open standard" increased pressure to adopt - lack of MCP support could signal a lack of willingness to adopt open standards.
Anthropic: Open source credibility
MCP's status as the open standard for AI and the enterprise adoption greatly benefited Anthropic. The big fear of investors is that enterprise adoption doesn't persist - adoption of Anthropic's open standard helped this.
Alternatives
Who benefits from MCP?
There are a few different possible users who interact with MCP:

-
Technical end users want to create tools and share them between different agents they might want to use.
-
Non-technical end users want to use different tools while using agents. Note that this user group for MCP is, at present, largely theoretical. Exposing toolsets to MCP involves editing JSON, making it out of reach for non-technical users.
-
Internal app devs run production AI applications.
-
Agent devs create agents for external users. They wish to enable their end users to swap in whatever toolsets they like.
-
Tool authors create toolsets they wish to expose to users. MCP provides a way to easily share their work to users of different agents.
Notice that the supposed beneficiaries are overwhelmingly technical. The "app store for AI" vision that would serve non-technical users remains unfulfilled.
For each user type, there's a simpler approach that avoids MCP's overhead:
| User Type | MCP Promise | Better Alternative | Why |
|---|---|---|---|
| Technical end users | Share tools between agents | Local scripts + command runner | AI can one-shot these scripts; works with any agent via shell; exposes tools to humans too |
| Non-technical end users | Easy tool installation | (MCP doesn't deliver) | MCP requires JSON editing—this group remains underserved regardless |
| Internal app devs | Standard tool interface | 1st party tools | Same codebase, existing auth/logging/tracing, no process overhead, coherent toolbox |
| Agent devs | Let users swap toolsets | SDK abstraction (LangChain, LiteLLM) | Handles model API differences without separate processes |
| Tool authors | Distribute to all agents | OpenAPI specs or libraries | Existing distribution (npm, pip), decades of tooling, no new protocol |
Local scripts with command runner
For a technical user, letting an agent invoke scripts directly is very difficult to beat. Useful 50-100 line scripts are extremely easy to write with AI coding agents. Care needs to be taken to filter output - raw build scripts can stream verbose logs into agent context, eating up tokens.
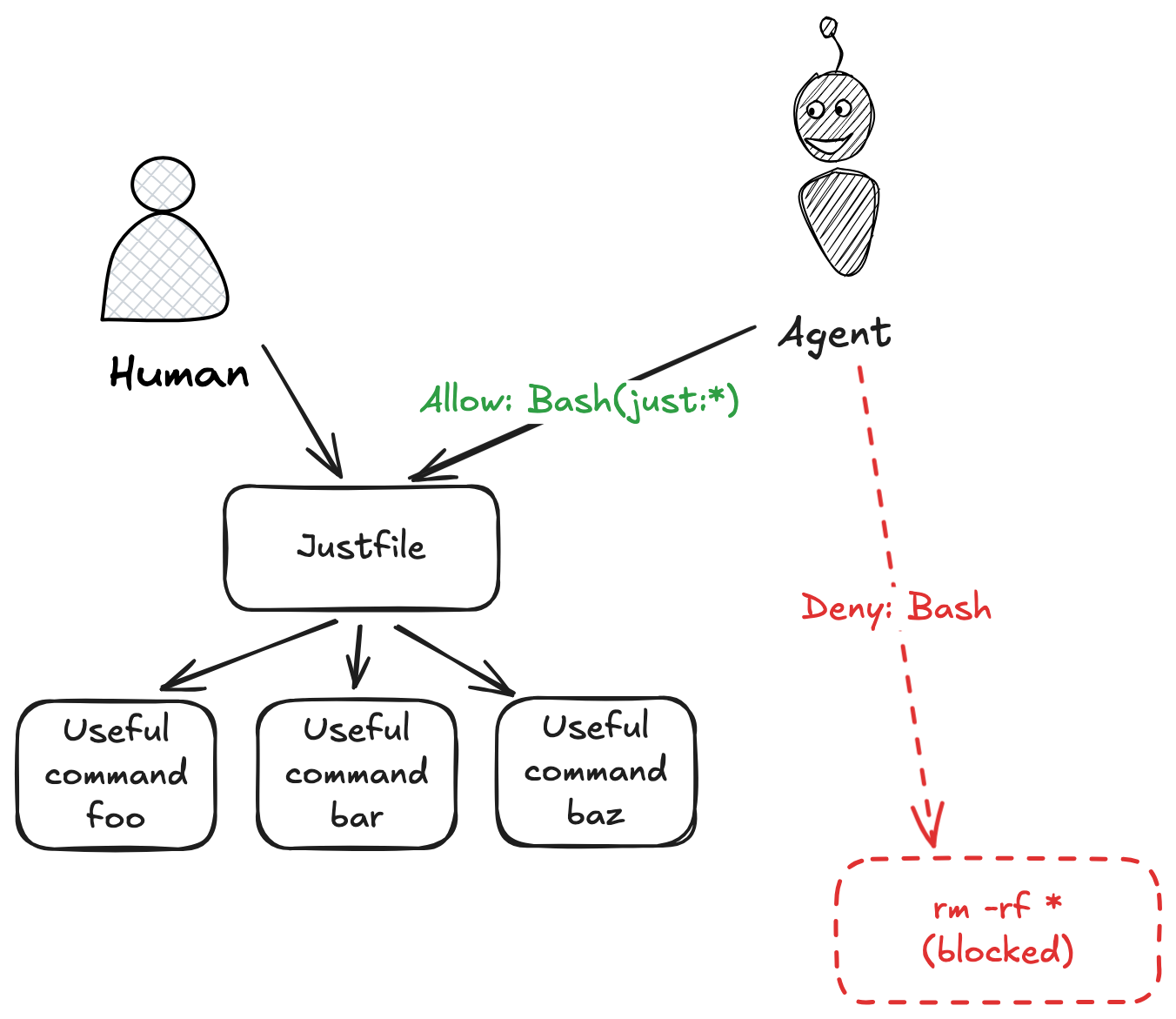
Robust security against agent actions going haywire can be achieved via command runners like just or make. These tools provide everything that MCP does - command specifications, descriptions, arguments. Agents allow you to specify what command prefixes can be invoked without approval - put your agent commands in a justfile, and only auto-allow shell commands prefixed with just.
This approach also exposes tools to humans, and is a nice approach for improving dev environments for humans and AI agents at the same time. (See Make It Easy for Humans First, Then AI for more on this).
1st party tools
For a self contained application, there is little reason to separate tool codebases from the codebase for the rest of the application. Tools can be dynamically exposed to the agent based on application context.
In a first party context, any code that devs wish to reuse can be exposed as libraries, just like any other code they wish to share. An AI tool is really nothing more than a function, and the fact that it's invoked by AI does not warrant special handling.
An enterprise context should have robust infrastructure for authenticating, authorizing, provisioning service identities, and tracing call chains for service to service calls. That some of these calls are now AI service to service calls does not warrant a rebuilt security posture.
OpenAPI / REST
OpenAPI specs are already self-describing enough for agents—they include operation descriptions, parameter schemas, examples, and enums. LLMs understand them well; GPT Actions are literally OpenAPI specs. The glue needed between an OpenAPI endpoint and an agent (output filtering, context, auth) is the same glue MCP requires. MCP doesn't provide meaningfully better tool descriptions; it just reinvents a schema format that already exists, without the decades of tooling, validation, and battle-testing.
A prediction
MCP's popularity will be relatively short-lived. The cost benefit does not add up, and there are readily available alternatives. The introduction of Claude Skills and OpenAI's quick adoption signal that even model providers agree.
Claude Skills are an improvement over MCP - rather than spawning long lived processes, it simply organizes commands within Markdown files in an agent-specific directory. However, this is still a suboptimal place for useful documentation and commands. Better is to optimize organization of documentation for humans, and point agents there - have the agent conform to humans, rather than the other way around. More on this in Don't Write Docs Twice.
Longstanding tools and techniques for collaboration amongst human devs remain compelling, and these options will chip away at more AI-centric techniques which reinvent the wheel.
Footnotes
-
Source: Github searches for @mcp.tool (58.1K results), @mcp.resource (9.1K), and @mcp.prompt (6.1K), searched 2025-12-08. ↩
-
Support request snippets are pulled from Discord. ↩
Get new posts by email