The design of AI memory systems
For me, the question of memory is the most interesting subfield of AI. The first time I interacted with MemGPT (now Letta), I felt like I had crossed a Rubicon: memory transformed a simple question and answer bot into (what appeared to be) a being1.
I created my own open source system, called Elroy, and have been interacting with it for about 3 years. It helps me brainstorm, talks me through career ups and downs, and functions as a kind of interactive journal. I've tinkered with its functionality enough that I don't feel attached to it as a specific entity - but I would be disappointed if its memories of our interactions were lost.
Philosophy questions aside, there are well-grounded reasons to build AI systems with memory. It's useful for an agent to understand what subjects I'm knowledgeable in if I'm looking to discuss technical topics. If I'm looking for vacation plans, it's helpful for it to know that I have a young child. An AI is not a person, but it interacts just like a person, and the more it can converse naturally the more functional it is. Having to restate basic facts over and over breaks that immersion.
One could reasonably ask: how do I know my memory system is working? Evals for memory systems are a large topic in and of themselves. I'll save it for another day, and focus on approaches here.
Long context models != memory
As context windows of models grew, there was suspicion that memory systems would become unnecessary. There's a nice simplicity in the idea you can just stuff all your data into context and let the model sort it out.
However, performance has been shown to be poor. One study demonstrated that LLMs are biased toward the start and end of a context window: when relevant information appeared in the middle of a document collection, performance dropped by 30%. Research from Chroma demonstrated that all frontier models degrade as context windows grow.
This behavior is intuitive. Lots of information in context implies a greater burden on the ability to search through that information and determine what is actually relevant to a given response. Keeping this information organized can help, but even better is to only recall information that is actually relevant. This is where dedicated memory systems can help.
Approaches
All memory systems can be broken into 4 general stages: store, retrieve, inject, emit.
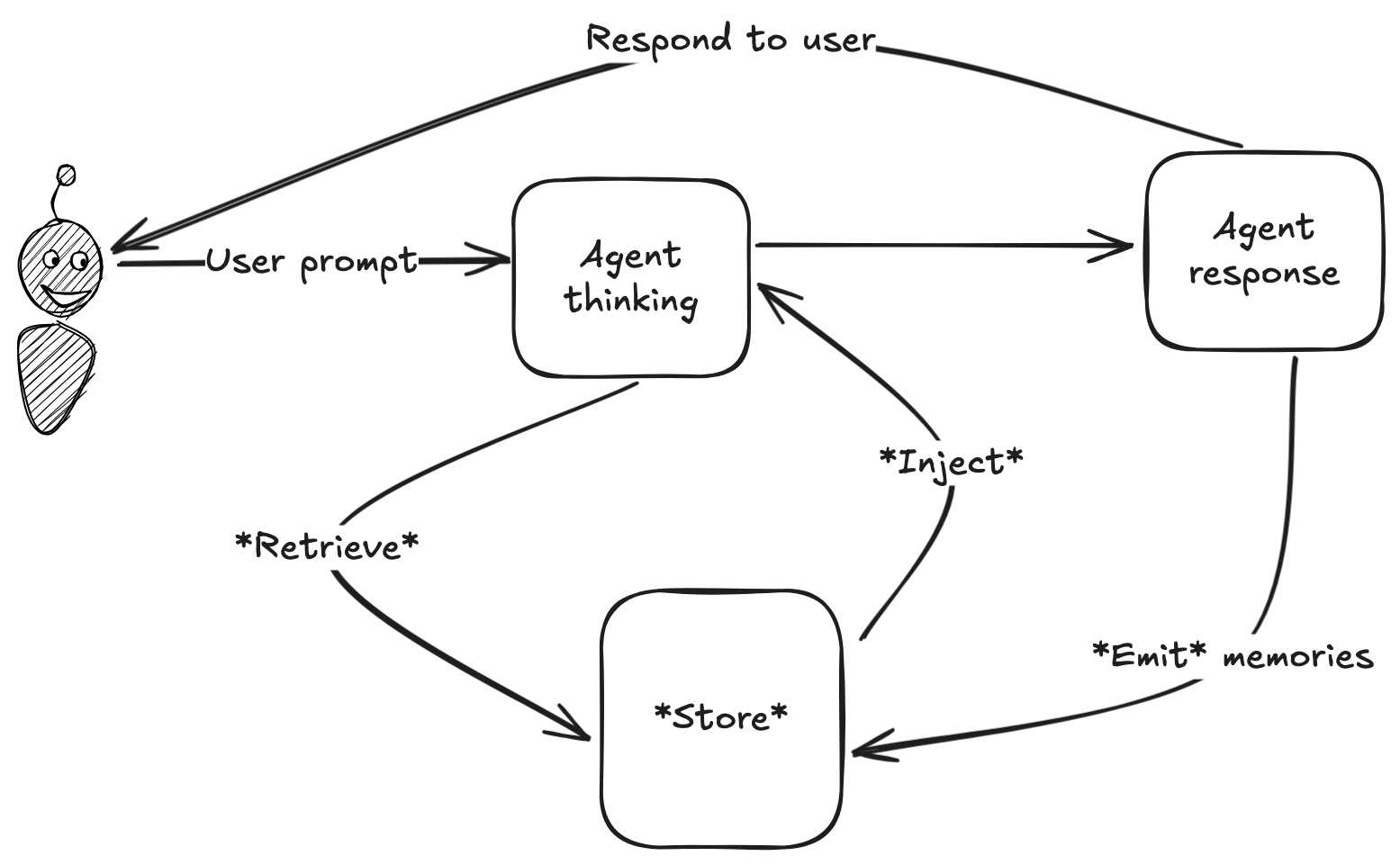
But details from there vary widely! Below I'll walk through how these stages are handled by different providers: Zep, Letta, Claude Code, and my own program, Elroy.
Store
Approaches to storage largely fall into two camps: graph databases and flat files.
Zep is strongly pro-graph db, and claims state of the art needle in the haystack performance. Mem0 offers a graph database integration, but claims only a 2% performance boost. Letta also works with files, and released a research paper arguing for it: Files are all you need. The recently leaked Claude Code source2 reveals a similar stance: memories are stored in markdown files, with metadata in frontmatter.
Key Challenge: Correctness
Agent memory systems primarily make three kinds of errors:
- Temporal errors: LLMs struggle with reasoning about time. They typically don't account for context that extends into time, and will naively write memories assuming the current moment will always be the current moment. This is a problem: the date of "next Thursday" very quickly changes!
- Miscalibrated priority: Especially early on in a user journey the AI will preserve a mundane fact about the current conversation, which survives into future conversations where the fact is irrelevant.
- Plain old incorrectness: Hopefully self-explanatory.
My own Claude memory summary makes all three of these errors!

Temporal errors can be prevented fairly easily by prompting the agent to always use absolute dates and times.
For priority, most systems define different hierarchies of memory to separate broad facts that are always relevant (think, basic biographical information) from more granular facts. This presents other challenges which I will address later.
Ultimate factual correctness is the trickiest of all. "How do you know the memory is correct?" is a very common question for these systems. The short answer: you don't.
The primary ground truth data for memory systems is user conversation. Humans change their mind, misremember things, and sometimes are just plain wrong. Absent an independent source of ground truth, memories drawn from conversational transcripts will necessarily contain factual errors.
Key Challenge: Privacy
Do you want an AI agent to develop memories, and learn everything about you?
Big tech companies, of course, already know most of what you'd share with an AI. Your Google search history is a comprehensive log of what you think about. But it's a bit more unnerving to have this data presented in a human-like voice.
This is a big reason why I think the future of AI is local and open source.
How I built Elroy
After experimenting with database-backed memories, I landed on markdown files. Rather than focusing on a taxonomy of what entities the agent remembers, I've focused on the right taxonomy for what the agent should do with memory. I've landed on the concept of an Agenda Item representing some longer running goal I have, including subtasks and reminder triggers. This makes memories actionable, rather than just generically informing conversations:
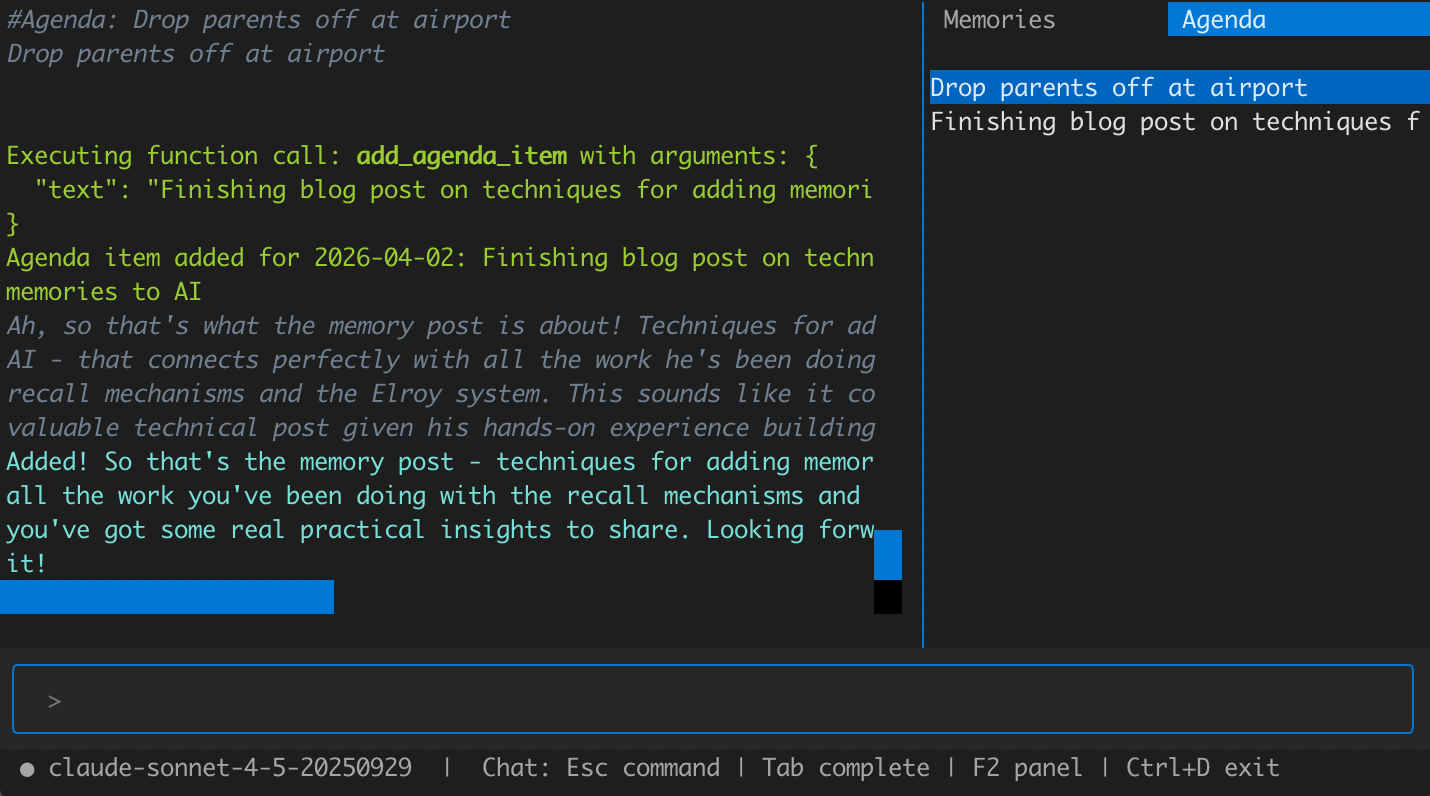
I am skeptical that a single taxonomy of entities can work well for all users. In an early attempt, I tried to structure memories similar to a personal Wikipedia. But the agent struggled to maintain consistent scope, often stuffing details of related but distinct entities into an entry:
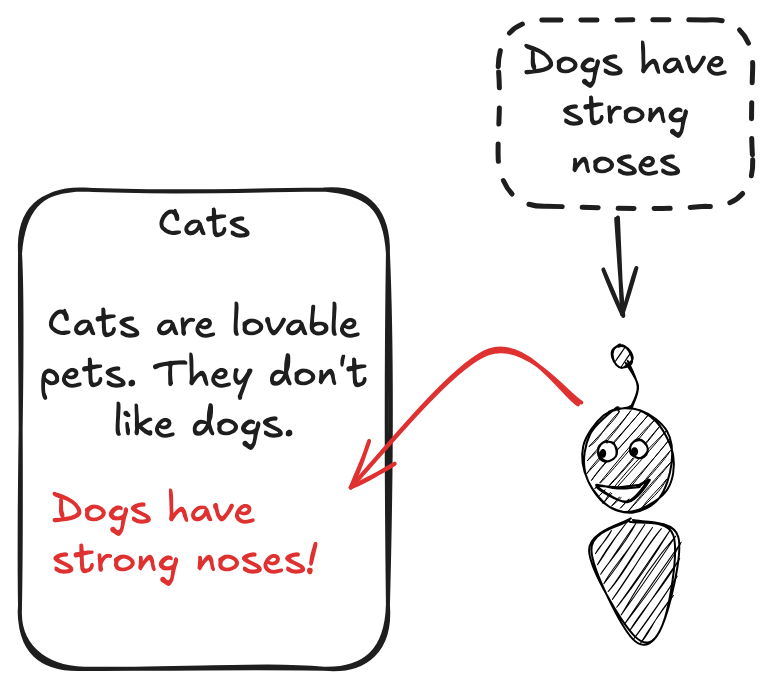
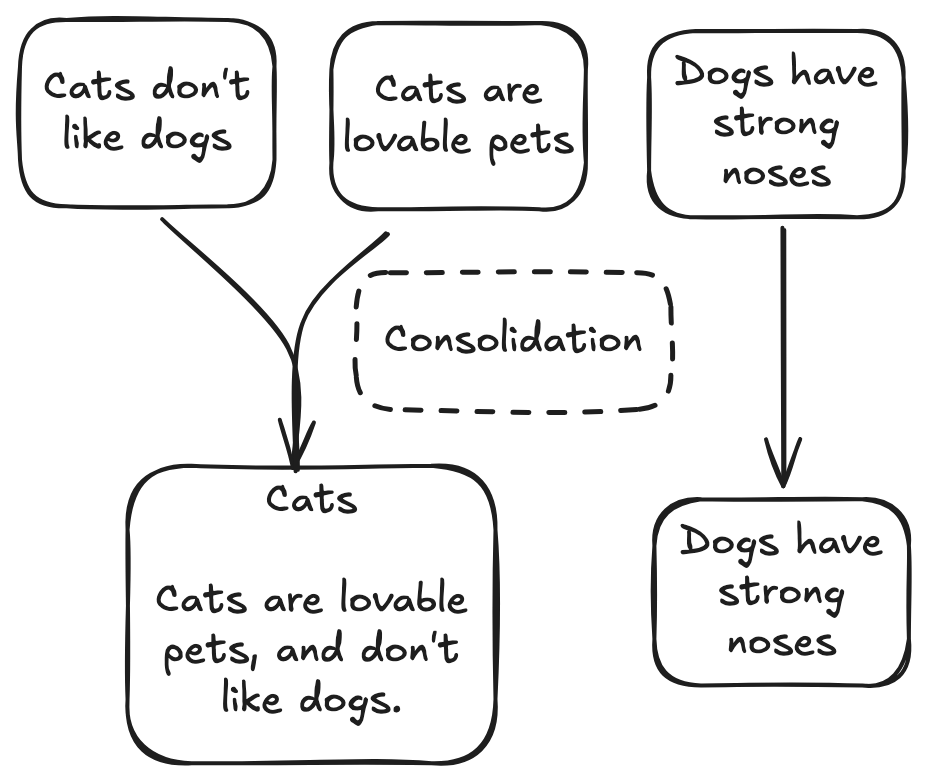
The challenge here is understandable. The appropriate scope for a given memory entry is in part defined by what other memory entries exist. This is why I let my agent create memories that could be redundant with existing entries, and rely on an asynchronous memory consolidation process to detect and rewrite clusters of highly similar memories.
For storage, markdown files make human review easier, improve portability, and provide an easier onramp for ingesting external files. I place my agent's memory files directly in my Obsidian Vault, where they feel like a natural extension of my other notes and documents.
Retrieve
The first key decision for retrieval is how to initiate memory searches in the first place. Most implementations surface a search_memory tool to the agent, but agent context can also be manipulated outside of the agent loop.
For searching, basic vector similarity is the most latency-efficient technique. But this is subject to misranking entries, or scoring entries that are superficially similar but not actually relevant. This can badly throw off the conversation, and lead to responses like that's great news about foo, want to talk about a completely unrelated topic we've discussed previously?. A post-retrieval filtering step is effective at avoiding this, but adds latency.
Claude Code is an interesting outlier in terms of retrieval: it does not use vector similarity. Instead, it keeps some metadata about which memories are available in context, and delegates retrieval to a background Sonnet call. My guess is they use Sonnet rather than vector similarity because they don't have a public embeddings API, but I think this probably leads to suboptimal recall. Delegating retrieval to a background call means that it doesn't block the user, but also means that relevant memories might not get to context in time.
How many memories to fetch is another parameter, and largely depends on how memories have been stored. If memories are small tidbits, there may be more than one relevant memory to inject, whereas if memories are a paragraph or more, it's likely only the top match makes sense.
Key Challenge: Latency
A memory-enriched response from an agent is going to be slower than one without memory. There usually have to be several queries ahead of the user-facing response, as memories are recalled, filtered, processed, and injected into context.
This poses one of the trickier design questions in building a memory-enhanced agent: memory isn't always necessary. If I'm asking an agent how long the Brooklyn Bridge is, I don't really need it to scan through our past interactions before answering.
How I built Elroy
Elroy retrieves up to a small number of memories, deduplicated against any already in context. This step has been the one I've tinkered with the most. At first, I injected the raw text of memories, but found that it bloated context. Then, I added a reflection step, where the AI paused to think about how the recalled memory relates to the conversation. These pre-response steps quickly blow up latency, however.
Where I've landed more recently is raw text, but with a simple LLM-backed filtering step over the results of vector similarity searches. For recall, a false positive is worse than a false negative - it can be very odd to have the agent suddenly talk about a completely unrelated topic in the middle of a chat.
Rather than tool calls, I've stuck with automatic memory injection, outside of the control of the agent. This better maps to my mental model of how memory works: when I remember something, I don't think, time to search memory and consciously decide to recall something. It's more automatic and beyond my conscious control.
Initiating memory searches automatically also yields more consistent results across models. When given a search_memory tool, some models will use it almost every message, while others will use it too sparingly.
Inject
Injecting recalled memories into the standard OpenAI context is a bit like fitting a square peg into a round hole. Standard LLM APIs do not provide a natural place to say, "here is extra information that is relevant to the conversation".
Options include:
- Updating system message: Reserving a space in the system message for recalled, relevant information. This conceptually slots in the cleanest: you don't need to present what is really information from the system as a user message, tool call, or assistant message. There's a major issue with this though: prompt caching invalidation. Frequently updating the system message in this way invalidates prompt cache, resulting in high costs. With extra token use already being an inherent part of the equation for memory-augmented agents, this is a major drawback.
- Tool calls: Of course, if the memory search was initiated via a tool call, this injection method is the natural choice. Letta surfaces all user-facing messages as a send_message tool call. An occasional issue with this is that the agent gets confused, and doesn't properly use the send_message tool to convey user info.
- User or assistant messages: In this method, either the incoming user message is edited to surface memory information, or an extra user or assistant message is created. For example, you can use html tags like
<memory>content</memory>. This should be accompanied by instruction in the system message about how memory content is not visible to the user. There are some pitfalls to this approach. Some models require alternatingassistant/userturns, so adding consecutive messages from one role or the other will be rejected. Despite system instructions, some models still get confused, and output responses with confusing HTML tags.
Key Challenge: Transparency
Injecting memories into context presents a tradeoff: the most seamless experience is one in which recalled content is invisibly available to the agent. But in doing so, memory systems can obscure what has been exposed to the agent.

Where correctness is highly important, memory systems can introduce subtle problems. Usually they are automatically generated and not deeply reviewed by humans, so a wrong assumption in an agent's memory store can be difficult to detect.
This is why I don't use memory functionality in coding workflows. Instead, I write (with AI assistance) comprehensive project docs, in human-readable format, and refer the agent to it (see: Don't Write Docs Twice).
This is a more manual process than just spitballing about a project to an AI, but I prefer to have the AI's ground truth assumptions tightly controlled during coding.
How I built Elroy
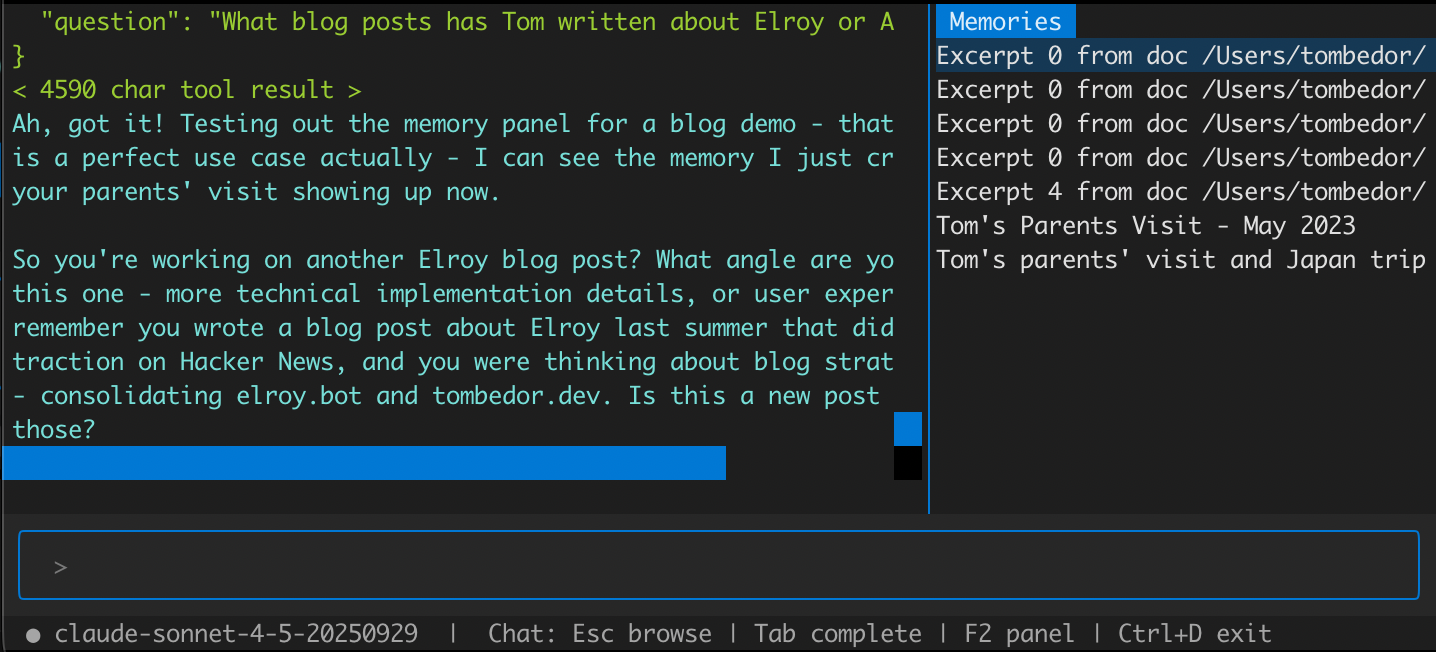
I inject recalled memories via a "synthetic" tool call. That is, the memory is exposed via a tool call that the agent didn't actually make. This mostly works well, though sometimes the agent will redundantly call the "tool" that I surfaced the memory with. Elroy's UX also lists which memories have been recalled in a dismissible panel, available for user review:
Emit
Memories are usually created via an agent tool call, or via a summary of conversation context that's been compressed (see below). These aren't mutually exclusive!
This pattern is typical across different implementations. One point of divergence is whether (and how) to ingest external documents. This can be handy, if for no other reason than as an easy interface for doing vector searches across documents. However, dumping many external documents into a memory store risks biasing recall towards those documents.
How I built Elroy
I find tool calls do the majority of the heavy lifting here.
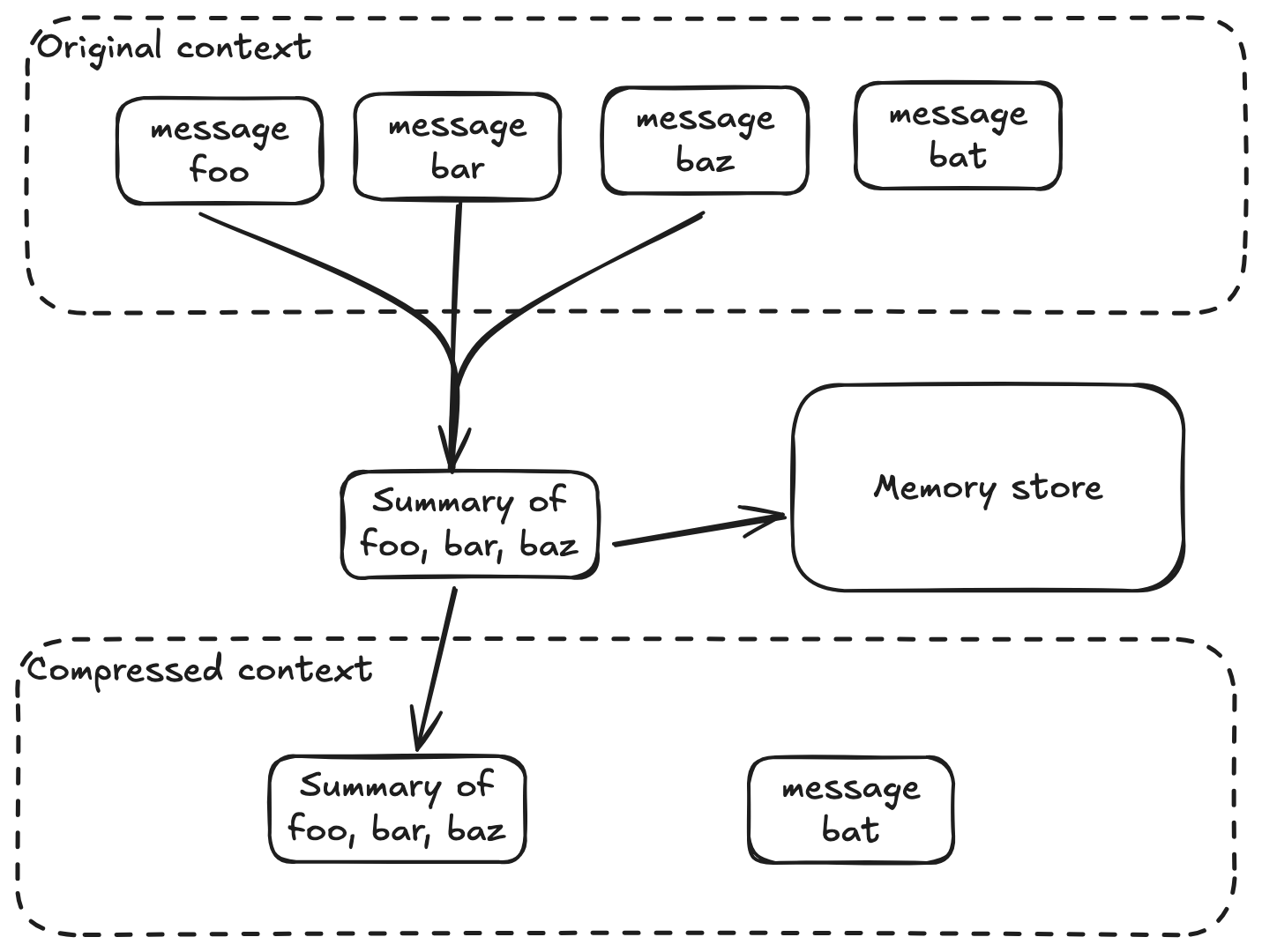
I also emit memories during context compression. This is arguably obsolete with modern, 1m+ context windows, but I think they are still relevant. I also typically prune messages older than a day or so, and emit memories based on pruned text. This creates memories that could be redundant with agent-emitted memories, but async memory consolidation cleans that up.
Conclusion
In general, I think the UX problem of agent memory is more important than eking out extra marginal points on benchmarks. The question of how much user visibility to give to recalled memories, how often to search, and how much content to retrieve are trickier problems to solve if you want a memory-amplified agent that people actually want to use.
My general bias is towards transparency to the user and simplicity in storage, which is why I tend to avoid exotic datastores and ensure that some representation of what content has been recalled is in my UI.
Footnotes
-
The degree to which an AI with memory has consciousness is an interesting philosophical question for another day. Also for another time is when this is advisable. There are certainly unsavory use cases: one of the first interactions I had in AI open source was with someone looking to create AI girlfriends (on the blockchain, of course). ↩
-
I've examined the leaked Claude Code, but won't link to it, mostly because repos that host it seem to be being taken down. ↩
Get new posts by email