AI Bots Are Making Anonymity Untenable
· 4 min read
"I would have written a shorter letter, but I did not have the time."
— Mark Twain1
This post describes how to write a short document for your teammates. The documents under discussion are commonly referred to as "one-pagers", and are distinct from engineering design docs or other more formal engineering docs.
A one pager might be written to:
It wasn't actually him but you get the point ↩
Model Context Protocol (MCP) has taken off as the standardized platform for AI integrations, and it's difficult to justify not supporting it. However, this popularity will be short-lived.
Some of this popularity stems from misconceptions about what MCP uniquely accomplishes, but the majority is due to the fact that it's very easy to add an MCP server. For a brief period, it seemed like adding an MCP server was a nice avenue for getting attention to your project, which is why so many projects have added support.
I'm working on an iPhone app called Tack. I have a terrible time remembering things, and have resorted to a patchwork of emails to myself and disorganized notes. I find reminder apps frustrating, the pre-AI ones aren't smart enough, and the AI ones treat every input like an invitation to have a conversation. Tack shoots for a middle ground:

I recently wrote about optimizing repos for AI, and since then I've been maintaining separate docs for humans (README, contributing guides) and AI agents (.cursorrules, CLAUDE.md, etc.). The problem? I keep writing the same information twice.
A colleague recently complained to me about the hassle of organizing information in AGENTS.md / CLAUDE.md. This is the mark of a real adopter - she has gone through the progression from being impressed by coding agents to being annoyed at the next bottleneck.
When I'm thinking about optimizing repos for agents, I'm looking to accomplish three main goals[^1]:
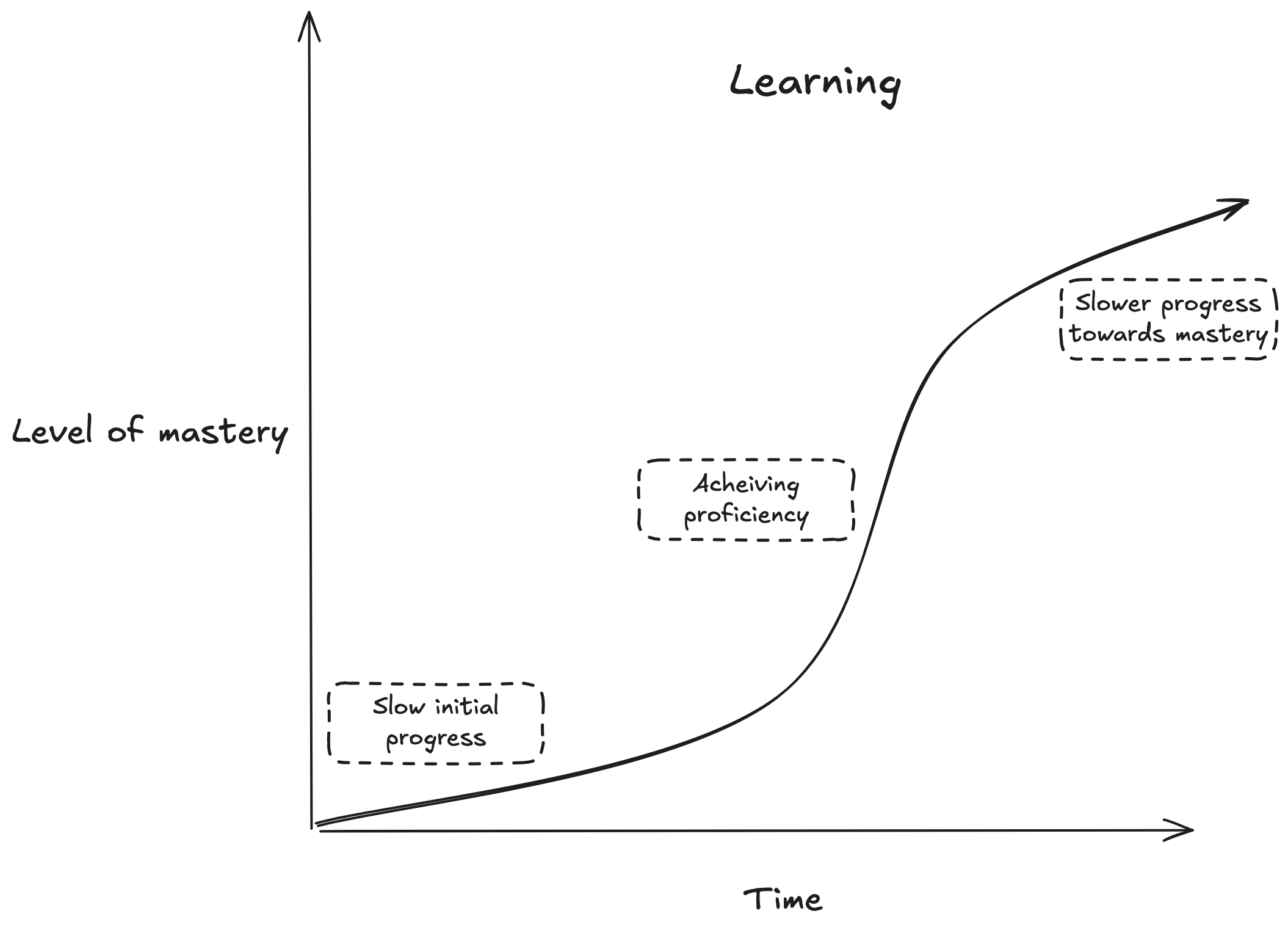
Before AI, learners faced a matching problem: learning resources have to be created with a target audience in mind. This means as a consumer, learning resources were suboptimal fits for you:
$topic_of_interest, but have knowledge in related topic $related_topic. But finding learning resources that teach $topic_of_interest in terms of $related_topic is difficult.$topic_of_interest, you really need to learn prerequisite skill $prereq_skill. But as a beginner you don't know you should really learn $prereq_skill before learning $topic_of_interest.$topic_of_interest, but have plateaued, and have difficulty finding the right resources for $intermediate_sticking_pointRoughly, acquiring mastery in a skill over time looks like this:
A core challenge of using LLM's to build reliable automation is calibrating how much autonomy to give to models.
Too much, and the program loses track of what it's supposed to be doing. Too little, and the program feels a bit too, well, ordinary[^1].
For LLM-based applications to be truly useful, they need predictability: While the free-text nature of LLMs means the range of acceptable outcomes is wider than with traditional programs, I still need consistent behavior: if I ask an AI personal assistant to create a calendar entry, I don't want it to order me a pizza instead.
While AI has changed a lot about how I develop software, one crusty old technique still helps me: tests.
This is a brief overview of my advice for new grads and junior software engineers. I'm been in the industry for about 8 years, and worked my way into engineering without a computer science degree. I've worked in both startups and medium-sized companies over the past 8 years.
As is the case with lots of tech writing, my advice will be skewed towards working in the San Francisco bay area, without needing visa sponsorship. Location and residency status are major factors to think about.
Other engineers with similar levels of experience as mine will disagree with some or all of it.